The ODSv2 is developed open-source on GitHub.
Features
Define ETL pipelines.
For extraction, we support the protocol HTTP, and data formats CSV, JSON, and XML. Data imports can be scheduled in a cron-like way to keep the data up to date. In the UI, we support users with a live preview showing how the configuration renders the data.
For transformation, we offer JavaScript code snippets that run in a sandbox. Via the UI, we support users with a code editor and show the transformed data in a live preview.
For loading, we offer an HTTP API to download the different data sets based on their import time. Currently, we are working on an additional GraphQL API that allows clients to query the data they need instead of downloading blobs.
Additionally, we provide notifications to users or client applications via HTTP webhooks, post into Slack channels, or offer integration with Google Firebase Notifications to push notifications directly to mobile apps.
Define data schema (in work).
Users can optionally specify the schema of the data via JSONschema. We offer schema recommendations in a semi-automated way that allows users to adapt the schema suggestion. When a schema is specified the data flowing through the system is validated against the schema to allow health checks of data sources and pipelines. Additionally, we generate a GraphQL API from the supplied schema to allow users to query exactly the data they need instead of supplying data blobs.
Demo
Architecture
We compose our architecture of different microservices. Communication between microservices utilizes eventing over AMQP, and communication with the UIs or other clients is facilitated over RESTful HTTP.
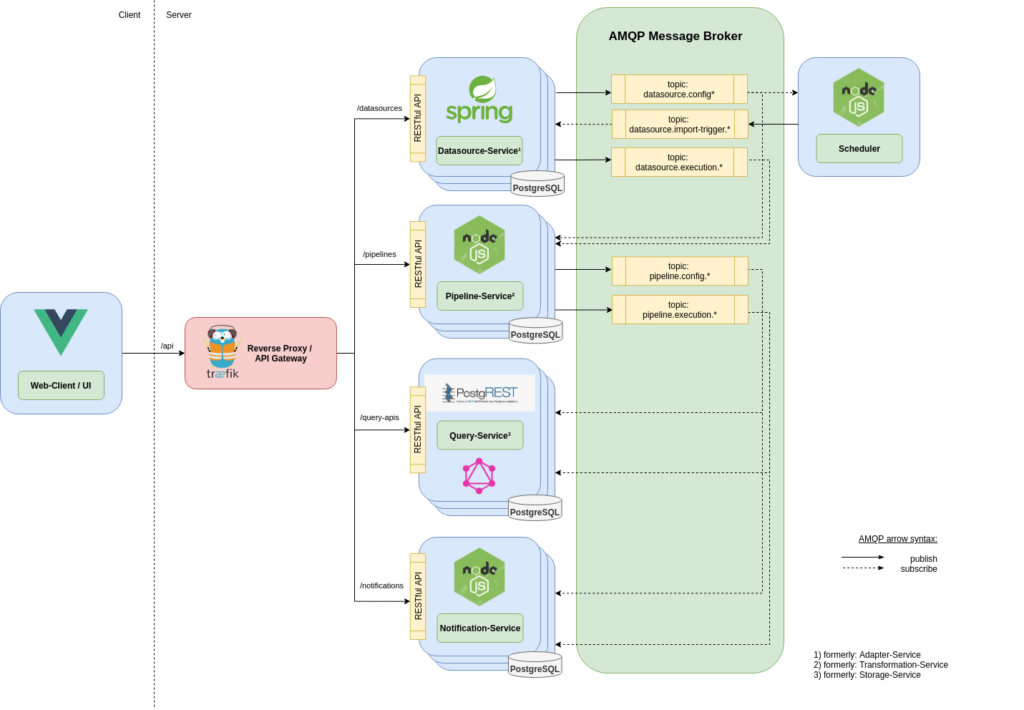
More fine-granular, the following presentation depicts the specifics of the ODSv2 and explains the design decisions we made: